隨著企業(yè)數(shù)據(jù)量的持續(xù)增長(zhǎng),如何高效管理海量數(shù)據(jù)并挖掘其價(jià)值,已成為企業(yè)數(shù)字化轉(zhuǎn)型過(guò)程中的關(guān)鍵挑戰(zhàn)。阿里云數(shù)據(jù)庫(kù)服務(wù)RDS(關(guān)系型數(shù)據(jù)庫(kù)服務(wù))和POLARDB(云原生數(shù)據(jù)庫(kù))作為企業(yè)級(jí)數(shù)據(jù)庫(kù)解決方案,提供了強(qiáng)大的數(shù)據(jù)存儲(chǔ)與處理能力。而X-Pack Spark作為阿里云上的大數(shù)據(jù)計(jì)算與分析服務(wù),能夠與RDS和POLARDB無(wú)縫集成,實(shí)現(xiàn)數(shù)據(jù)的高效歸檔、計(jì)算和存儲(chǔ)支持。本文將介紹將RDS和POLARDB數(shù)據(jù)歸檔到X-Pack Spark的最佳實(shí)踐,幫助企業(yè)構(gòu)建靈活、可擴(kuò)展的數(shù)據(jù)處理架構(gòu)。
一、數(shù)據(jù)歸檔背景與需求
在業(yè)務(wù)運(yùn)營(yíng)中,RDS和POLARDB通常存儲(chǔ)著核心交易數(shù)據(jù)和實(shí)時(shí)業(yè)務(wù)信息。隨著數(shù)據(jù)量的積累,數(shù)據(jù)庫(kù)的存儲(chǔ)壓力增大,查詢(xún)性能可能下降,同時(shí)存儲(chǔ)成本也會(huì)上升。將歷史數(shù)據(jù)或冷數(shù)據(jù)歸檔到X-Pack Spark,可以有效減輕數(shù)據(jù)庫(kù)負(fù)載,降低成本,并利用Spark的強(qiáng)大計(jì)算能力進(jìn)行離線(xiàn)分析、機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘。常見(jiàn)應(yīng)用場(chǎng)景包括:歷史交易數(shù)據(jù)歸檔、日志數(shù)據(jù)分析、用戶(hù)行為分析等。
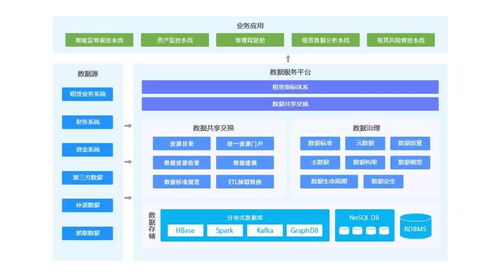
二、歸檔架構(gòu)設(shè)計(jì)
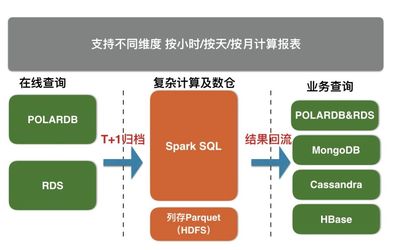
為實(shí)現(xiàn)高效的數(shù)據(jù)歸檔,建議采用以下架構(gòu)設(shè)計(jì):
- 數(shù)據(jù)源層:RDS和POLARDB作為數(shù)據(jù)源,存儲(chǔ)實(shí)時(shí)或熱數(shù)據(jù)。通過(guò)數(shù)據(jù)庫(kù)的內(nèi)置工具(如RDS的備份功能或POLARDB的導(dǎo)出工具)將數(shù)據(jù)導(dǎo)出為兼容格式(如CSV、Parquet或ORC)。
- 傳輸層:使用阿里云Data Transmission Service(DTS)或自定義腳本,將導(dǎo)出的數(shù)據(jù)傳輸?shù)綄?duì)象存儲(chǔ)服務(wù)OSS中。OSS作為中間存儲(chǔ),確保數(shù)據(jù)的安全性和可訪(fǎng)問(wèn)性。
- 計(jì)算存儲(chǔ)層:X-Pack Spark從OSS中讀取數(shù)據(jù),進(jìn)行ETL(提取、轉(zhuǎn)換、加載)處理、歸檔存儲(chǔ)以及計(jì)算分析。Spark支持多種數(shù)據(jù)格式,并可集成HDFS或OSS作為持久化存儲(chǔ),實(shí)現(xiàn)數(shù)據(jù)的長(zhǎng)期保留和快速查詢(xún)。
- 應(yīng)用層:通過(guò)Spark的API或SQL接口,業(yè)務(wù)應(yīng)用可以直接訪(fǎng)問(wèn)歸檔數(shù)據(jù),進(jìn)行報(bào)表生成、趨勢(shì)分析或機(jī)器學(xué)習(xí)任務(wù)。
三、實(shí)施步驟
- 數(shù)據(jù)準(zhǔn)備:在RDS或POLARDB中識(shí)別需要?dú)w檔的數(shù)據(jù),例如通過(guò)時(shí)間戳篩選歷史記錄。確保數(shù)據(jù)導(dǎo)出前進(jìn)行備份,避免影響線(xiàn)上業(yè)務(wù)。
- 配置數(shù)據(jù)傳輸:使用DTS設(shè)置數(shù)據(jù)同步任務(wù),將數(shù)據(jù)從數(shù)據(jù)庫(kù)導(dǎo)出到OSS。DTS支持全量和增量同步,適用于不同歸檔頻率的需求。如果需要自定義邏輯,可以編寫(xiě)Spark作業(yè)直接連接數(shù)據(jù)庫(kù)讀取數(shù)據(jù)。
- Spark作業(yè)開(kāi)發(fā):在X-Pack Spark中創(chuàng)建作業(yè),定義數(shù)據(jù)讀取、轉(zhuǎn)換和存儲(chǔ)邏輯。例如,使用Spark SQL將數(shù)據(jù)從OSS加載到DataFrame,進(jìn)行清洗和聚合后,保存到HDFS或OSS的指定目錄。Spark的分布式計(jì)算能力可以高效處理TB級(jí)數(shù)據(jù)。
- 監(jiān)控與優(yōu)化:通過(guò)阿里云監(jiān)控服務(wù)跟蹤數(shù)據(jù)歸檔任務(wù)的性能,包括傳輸速率、Spark作業(yè)執(zhí)行時(shí)間和資源使用情況。根據(jù)需求調(diào)整Spark集群配置,如增加Executor數(shù)量或優(yōu)化內(nèi)存分配,以提升效率。
- 安全與權(quán)限管理:確保數(shù)據(jù)傳輸和存儲(chǔ)過(guò)程中加密(如SSL/TLS),并設(shè)置訪(fǎng)問(wèn)控制策略,防止數(shù)據(jù)泄露。使用RAM(資源訪(fǎng)問(wèn)管理)角色授權(quán)Spark訪(fǎng)問(wèn)OSS和數(shù)據(jù)庫(kù)。
四、優(yōu)勢(shì)與收益
通過(guò)將RDS和POLARDB數(shù)據(jù)歸檔到X-Pack Spark,企業(yè)可以獲得以下收益:
- 成本優(yōu)化:減少數(shù)據(jù)庫(kù)存儲(chǔ)開(kāi)銷(xiāo),利用Spark的彈性計(jì)算資源按需付費(fèi)。
- 性能提升:釋放數(shù)據(jù)庫(kù)資源,提高實(shí)時(shí)查詢(xún)性能,同時(shí)Spark支持并行處理,加速數(shù)據(jù)分析。
- 靈活性增強(qiáng):支持多種數(shù)據(jù)格式和計(jì)算場(chǎng)景,便于集成AI/ML工具,如MaxCompute或PAI。
- 可擴(kuò)展性:Spark集群可水平擴(kuò)展,應(yīng)對(duì)數(shù)據(jù)量增長(zhǎng),確保長(zhǎng)期數(shù)據(jù)管理能力。
五、總結(jié)與建議
數(shù)據(jù)歸檔是現(xiàn)代化數(shù)據(jù)架構(gòu)的重要組成部分。結(jié)合RDS、POLARDB和X-Pack Spark,企業(yè)可以構(gòu)建一個(gè)高效、經(jīng)濟(jì)的數(shù)據(jù)生命周期管理方案。建議在實(shí)踐中,根據(jù)業(yè)務(wù)需求定期評(píng)估歸檔策略,例如設(shè)置自動(dòng)化歸檔任務(wù),并利用Spark的監(jiān)控工具進(jìn)行持續(xù)優(yōu)化。通過(guò)這一最佳實(shí)踐,企業(yè)不僅能降低運(yùn)營(yíng)成本,還能挖掘數(shù)據(jù)深層價(jià)值,驅(qū)動(dòng)業(yè)務(wù)創(chuàng)新。